From Legacy to Leading-Edge: Navigating the Modernization Journey [Part 2]

Note: This is the second part of a series. You can find the first part here.
Challenge #4: Observability
During the transition period, I participated in numerous incident calls, which were often frustrating due to a lack of data points for troubleshooting. The situation mirrored climbing a mountain in dense fog, with little visibility into the problems at hand. Logs were unclear, and we had no traces or metrics. Moreover, as we functioned as a bridge between external customers and internal APIs managed by various internal teams, most issues stemmed from failures in downstream services rather than our API Gateway. However, without evidence to support this, we were frequently pressured by teams claiming it was our responsibility. Identifying root causes often took several days, and while some issues could be reproduced in lower environments, data and configuration discrepancies made others impossible to replicate.

Recognizing the urgent need for improvement, we focused on three pillars of observability: logs, traces, and metrics. We enhanced our logging mechanism to produce more detailed and structured logs, incorporating relevant event metadata. We also instrumented our code to emit traces to the AWS X-Ray service, allowing us to review the details of downstream API calls, including both requests and responses. Additionally, we established key metrics for the AWS services we utilized and created CloudWatch alarms based on severity levels. When alarms are triggered, alerts are sent to an SNS topic, which engineers subscribe to, ensuring they are notified as soon as any issues arise.
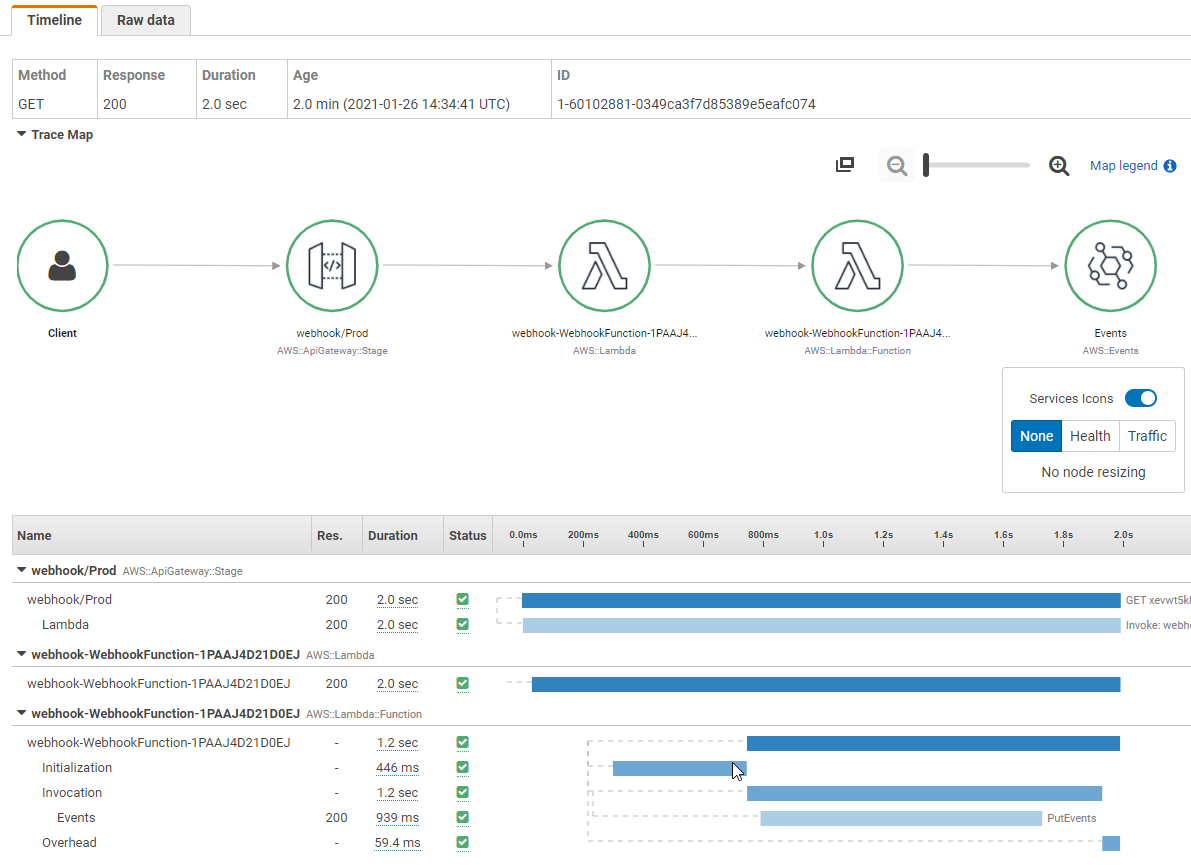
Finally, we created CloudWatch dashboards to visualize vital metrics, enabling us to assess overall system health with a few simple visualizations. With this modernization in observability, we greatly improved our issue resolution speed; what previously took days can now be completed in just 15 minutes. With logs and traces in place, we can swiftly determine whether an issue originates within our layer or in a downstream service. By reviewing the requests sent to the downstream system and the responses received, we have concrete evidence to provide the respective teams for resolution. Additionally, our ability to track availability and error rates extends not only to our APIs but also to downstream ones.
Challenge #5: DevSecOps
When it came to security, the situation we inherited displayed an interesting imbalance. The build process was automated using Jenkins, but the Jenkins server was hidden behind a complex virtual machine setup that made it hard to reach - strict security measures made it prohibitively difficult to use. At the same time, sensitive configurations and secrets needed by applications were stored in plain text in source control, completely undermining security.
We needed to rectify these poor practices to ensure that our solution were secure and that the delivery process itself was safe. We started by replacing Jenkins with GitHub Actions, a logical transition since we stored our code in GitHub. Now, all engineers could utilize and review Actions as long as they had repository access. For higher-stakes actions - such as deployments to UAT and PROD - we established a manual approval gate handled by the technical lead.

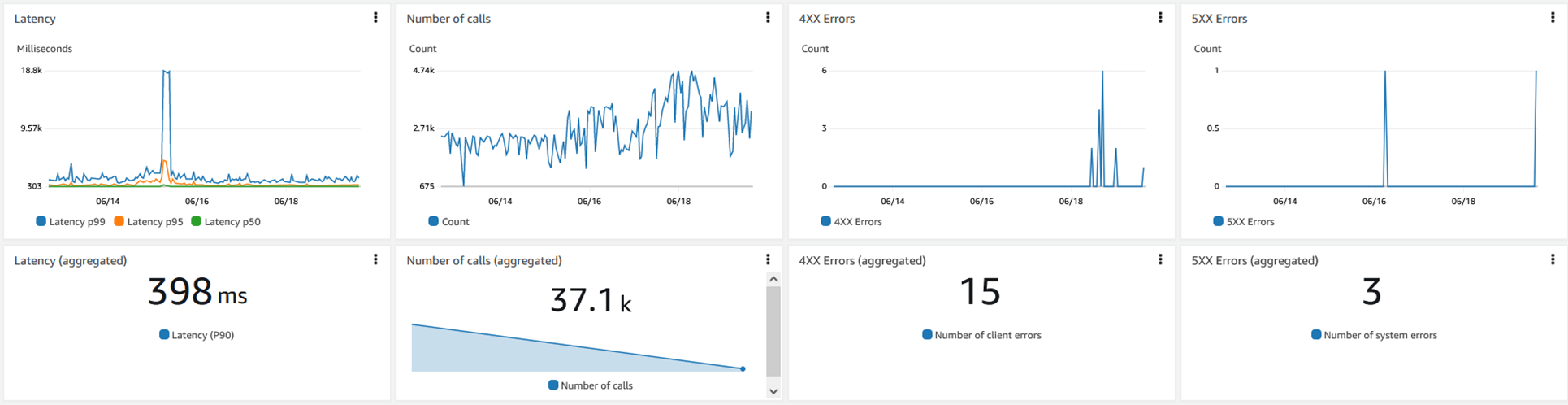
As we leveraged more of GitHub’s capabilities, we integrated Dependabot to continually assess our third-party dependencies and automatically raise pull requests for security updates. With a fully automated verification pipeline in place, if all necessary checks pass, we can merge such pull requests without additional manual testing.
Finally, we moved our application secrets to AWS Secrets Manager, integrating our actions and applications to retrieve secrets from this secure, AWS-managed service. This transition eliminated the security risks associated with storing secrets in plain text.
By addressing these poor practices, we not only improved our security posture but also made the process more engineer-friendly. Engineers now have visibility into when and why actions might fail. Security patches are also applied automatically via Dependabot, and our secrets are securely stored in AWS Secrets Manager.
Challenge #6: Quality
When I joined the API Gateway workstream, the quality of work was considerably lacking, much like a neglected garden overrun with weeds. As previously mentioned, the process for making changes was chaotic, which led to poor quality, as tasks were often completed in haste. There were no automated tests; everything was verified manually. Under time constraints, team could only check the specific changes made, leaving no time for comprehensive regression testing to ensure that other system components had not been adversely affected. With only two AWS cloud environments available - UAT and PROD - testing was limited, particularly since we could not run applications locally. Deploying faulty changes to UAT would upset business stakeholders and external partners reliant on this environment for verification.

To enhance our quality practices, we began by provisioning a dedicated DEV environment exclusively for our engineers - this was akin to establishing a separate lane in a highway for engineers to use. This environment allowed engineers the freedom to deploy and verify changes without affecting others. Next, we constructed an automated testing pyramid. As we modernized the codebase, we wrote unit tests to verify behavior for all cases. We then established an integration testing suite to assess higher-level functionality with real integrations, covering HTTP request handlers, databases, and messaging systems. Finally, we implemented an end-to-end testing suite to validate workflows with all components in place.
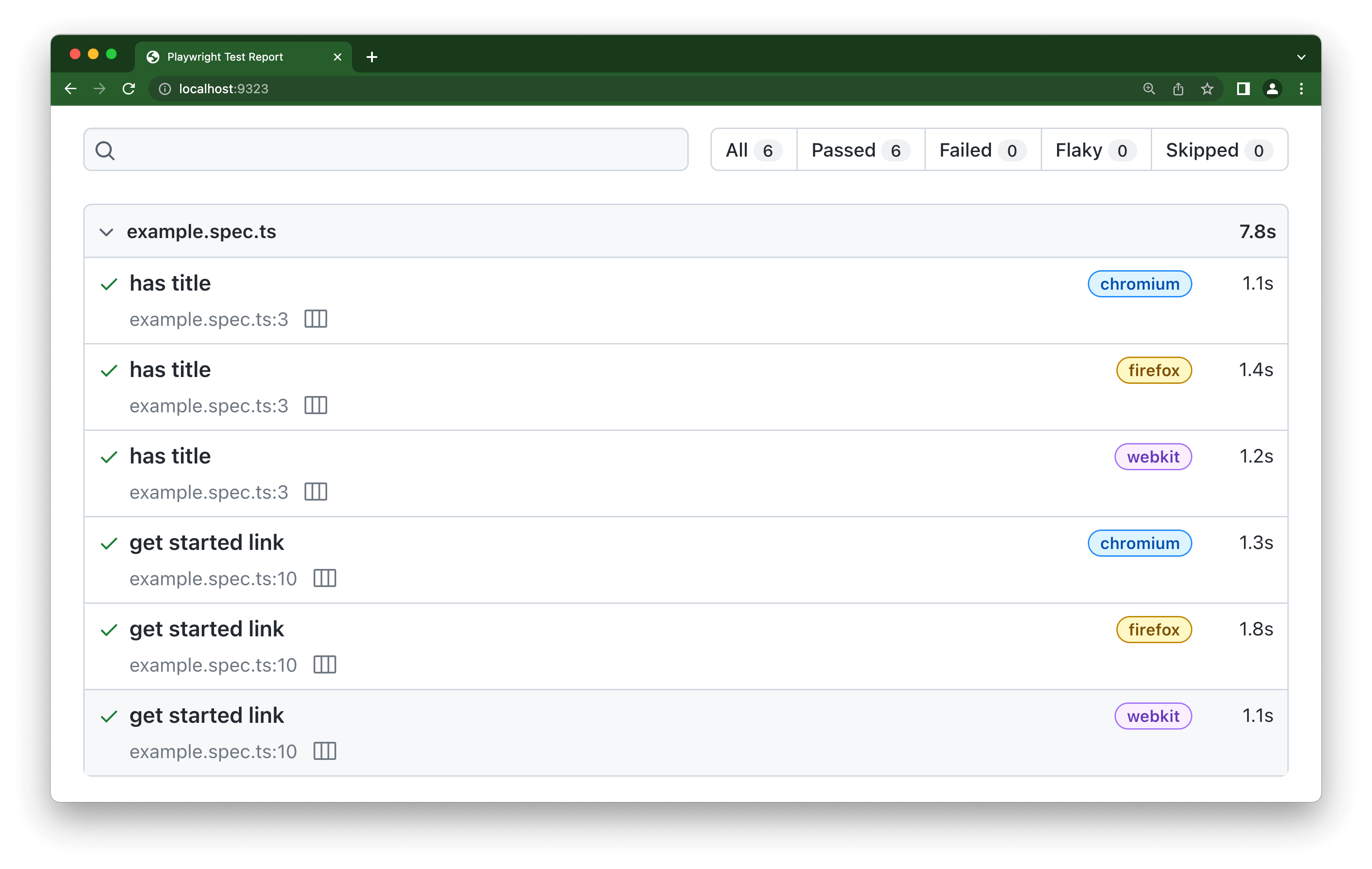
Automated tests were integrated into our build pipeline, allowing us to run them before any change was made. What previously took days to verify manually can now be accomplished in just 15 minutes through automation, enabling us to confidently validate changes before release.
Challenge #7: Rollout of Modernized Features
Modernizing a system actively in use is a challenging endeavor - like changing an engine on a moving car. A deliberate process and structure are necessary to ensure a smooth transition. Therefore, we employed incremental development using evolutionary coding patterns. One of the cornerstone patterns we utilized was “Branch by Abstraction” as explained by Martin Fowler here.
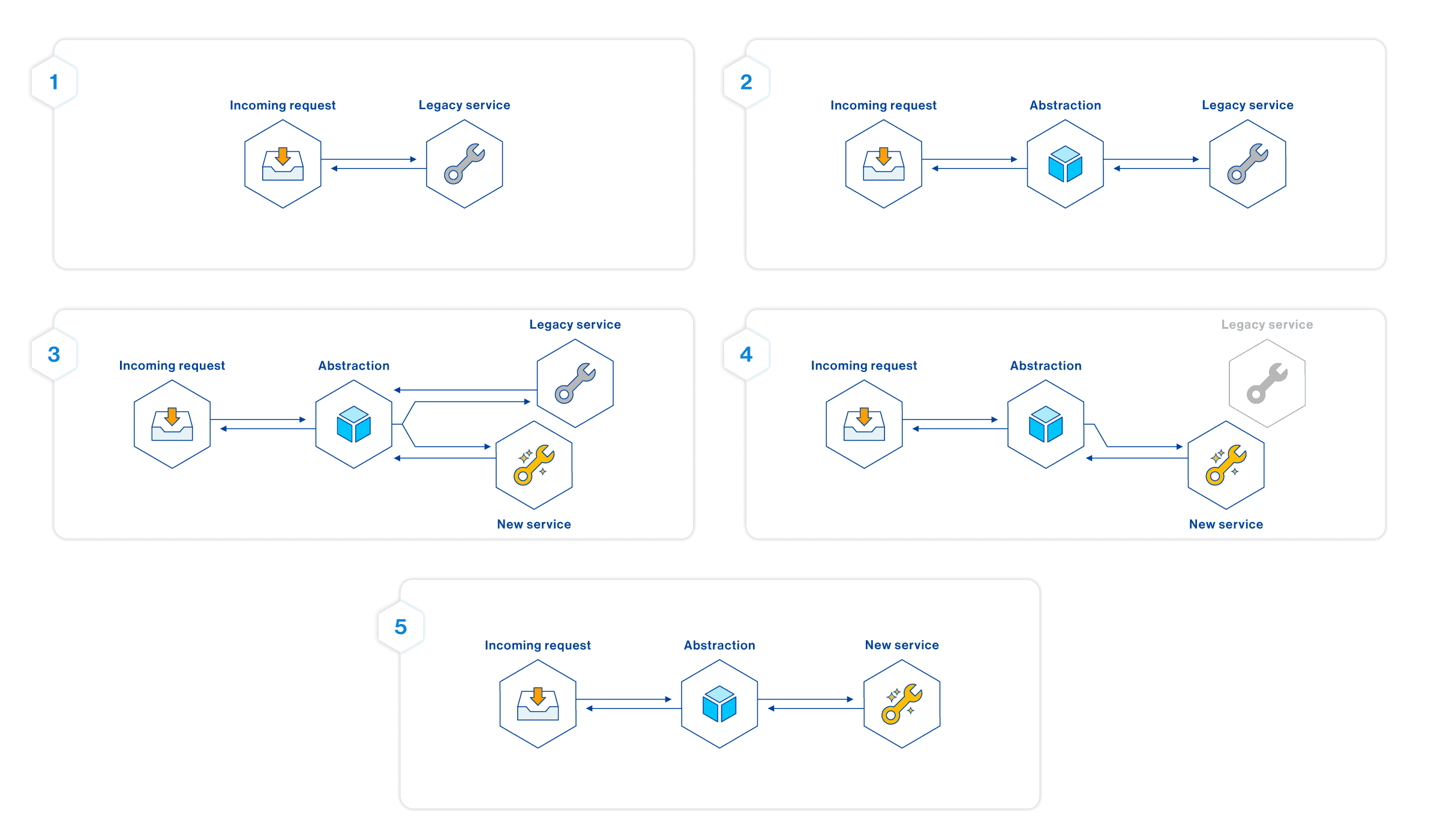
We applied this pattern in the following way when modernizing API endpoints:
- Create a new API handler attached to a beta version of the HTTP endpoint in API Gateway.
- Conduct incremental development and testing of the modernized logic via the HTTP endpoint’s beta version.
- Perform final verification of the modernized handler, which remains attached to the beta version.
- Switch over to attach the modernized handler to the production version of the HTTP endpoint.
- Monitor system behavior once the new handler is live with production traffic.
- Implement a rollback or hot-fix strategy in the event of significant issues.
- Remove old code after the transition period, as the need for rollback options is no longer relevant.
By adopting this pattern, we could incrementally develop and test the system. This approach proved particularly beneficial for modernizing complex endpoints, where development and testing required multiple sprints and release cycles. As modernized handlers were linked to the beta versions of HTTP endpoints, we could isolate testing across various environments.

Thanks to robust observability measures, we leveraged data and metrics to monitor switch-overs and verify that the modernized APIs behaved as expected. This method allowed us to define rapid rollback strategies, which came in handy several times.
Ultimately, we successfully modernized all API endpoints using this approach. Once the endpoints were modernized, extending them and adding new features became significantly easier and faster.
Final Remarks

Completing this project has provided me with valuable lessons and insights:
- Modernization is more than just adopting the latest technologies - it’s about the people, processes, and ways of working. Sometimes, changing the technology is easy, but altering established processes and mindsets is much more challenging.
- Clearly defining objectives for modernization is vital. A coherent vision, roadmap, estimated timelines, and business justification are necessary components.
- Once a vision is articulated, it should be supported by modern engineering practices that drive that vision forward. Assessing what is genuinely relevant and necessary is more crucial than simply chasing current industry trends.
- Continuously monitoring engineering maturity is essential. Making timely decisions and investments can help prevent the need for another extensive modernization effort in the near future.
- Listening to all stakeholders is fundamental to the success of modernization initiatives. Business stakeholders provide insights into business capabilities and goals; managers offer input on ways of working, processes, and team structures; and engineers bring forward the critical pain points they encounter daily.
This journey was not straightforward, and I am deeply grateful to all my colleagues who collaborated with me on this endeavor, tirelessly working to successfully modernize delivery and engineering for our client. We came, we saw, and we modernized.