Under the Hood of my Blog
Direction
When I made the decision to start blogging and had some content for posts ready, I had to decide where and how to publish them. Nowadays, there are many options for sharing content publicly:
- Wordpress
- Blogger
- Wix
- Hostinger
- Substack
These services are intuitive and allow bootstrapping a place to share ideas very easily and relatively cheaply. Services additionally offer SEO optimizations, marketing options and help you get more views, likes and comments. Sounds really great, right? Well, not for me.
My key driving factors for this blog are:
- I don’t care too much about views, reactions or any other features that these platforms offer. I just care about the content and the message that I want to convey.
- Since engineering is my second nature, I want to get my hands dirty, build stuff on my own, learn new things and share them with you.
As a result, I decided not to use any of these services and build a blogging solution on my own.

Requirements
As a technical solutions architect, I naturally approached this as a project that needs to be clarified and refined. Every project starts with a set of requirements, so I sat down and compiled a list of functional and non-functional requirements that the solution must satisfy.
| Requirement | Area |
|---|---|
| Solution must be based on a free web framework. | Architecture |
| Solution should be based on a free template that would offer opinionated defaults, but could also be fully customizable. | Architecture |
| Solution must be stored in a source control system. | Architecture |
| Solution must be deployed to a public cloud. | Infrastructure |
| Solution must have full styling customization. | Architecture |
| Solution must have the ability to provide basic analytics: page views, unique users. | Analytics |
| Infrastructure needed to run the solution must be cost efficient. | Infrastructure |
| Solution should be interesting and fun to implement. | Entertainment |
| Readers should be interested and keep reading posts. | Engagement |
| Solution must be performant. | Performance |
| Solution must be SEO optimized. | SEO |
As with most requirements, this list is far from perfect. Some requirements can be interpreted differently and that can lead to unexpected outcomes. All of us were in situations where the client expected something else to what was actually delivered.

So even though I am my own client, I used this as an exercise to improve my requirement refinement skills. After additional review, I improved the list:
| Requirement | How to verify if requirement is satisfied |
|---|---|
| Solution must be based on an open-source web framework. | Check if the framework is open sourced (e.g. has MIT license). |
| Solution should be based on a free template that would offer opinionated defaults, but could also be fully customizable. | Check if the template is open sourced (e.g. has MIT license). Use the template to successfully launch a demo project. Change the template to make some customization (e.g. add additional fields to blog posts). |
| Solution must be stored in the source control system. | Check if all the source code for the solution is stored in the source control repository. |
| Solution must be deployed to a public cloud. | Check if all components of the solution are deployed and running in the public cloud. |
| Solution must have the ability to accept custom CSS styling. | Check if the solution includes CSS styling code. |
| Solution must have ability to provide basic analytics: total page views for each entry since release of the blog, total unique users since release of the blog. | Check if the solution can calculate the required numbers. |
| Infrastructure needed to run the solution must cost less than 5 EUR per month. | Check credit card summary for total cost of cloud subscription each month. |
| Solution should be interesting and fun to implement. | Verify if I do not abandon this side-project and successfully launch it. |
| Each post should receive 50 unique reads in 2 weeks after the post is published. | Leverage analytics feature to verify if actual numbers match the goal. |
| Solution must pass Lighthouse report with no less than 90 scoring for SEO, performance, accessibility and best practices areas. | Open Lighthouse, run the report and match actual metrics with the goal. |
In my eyes, these revised requirements are more clear as we know how to verify them. Now that we have better requirements, let’s dive into the technical solution that would match them.

Architecture
The foundational element of this blogging solution is the Astro framework. Astro is the web framework for building content-driven websites like blogs, marketing, and e-commerce. Astro is best-known for pioneering a new frontend architecture to reduce JavaScript overhead and complexity compared to other frameworks. If you need a website that loads fast and has great SEO, then Astro is for you.
Here, you can read more about this framework - Getting started.
Astro has a huge list of templates to cover a variety of different areas - blogging, portfolio, documentation and e-commerce. Full list of templates can be found here - templates.
For my needs, I chose a blog template. This template has features that I found very useful and suitable for me:
- Blog posts are stored as Markdown documents in the source control system. I love writing Markdown as it is closer to the code than Word and satisfies my inner programmer.
- It has a minimal amount of features. No comments, no likes, no social integrations. Just a few pages of focused and pure content. That is what I love.
- Template has good defaults, but I was able to successfully and easily adapt it to my needs by writing some custom code. For example, I added tags functionality where I can specify one or multiple tags for each post if needed.
- Default Astro configuration bundles no JavaScript and serves HTML/CSS in a server-side rendering approach. This means that performance and SEO optimizations will be at its best.
Markdown post files follow a certain structure that Astro can parse and leverage within the internal rendering engine.
Here is an example markdown file:
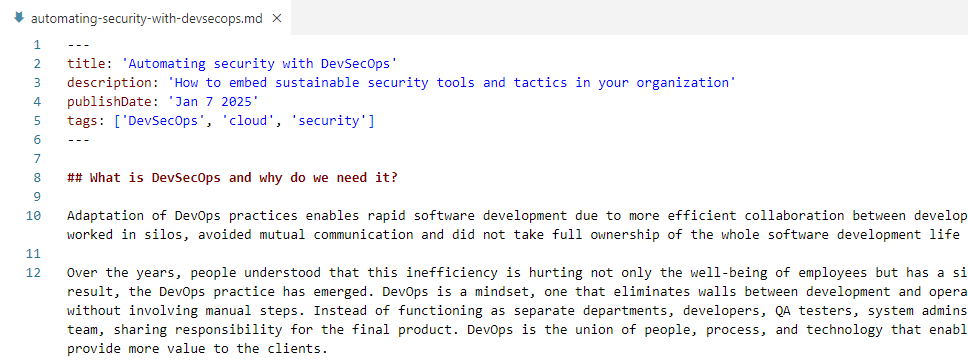
At the start of the file, there is a metadata block that defines post title, description, publish date and tags. Afterwards, we have the post content itself with markdown syntax.
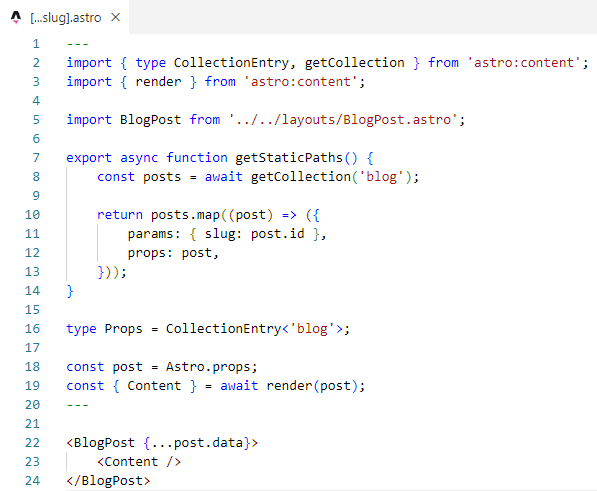
In the Astro code, there is a route that accepts slug from the path (e.g. automating-security-with-devsecops), reads the corresponding Markdown file and passes parsed data to visual components:
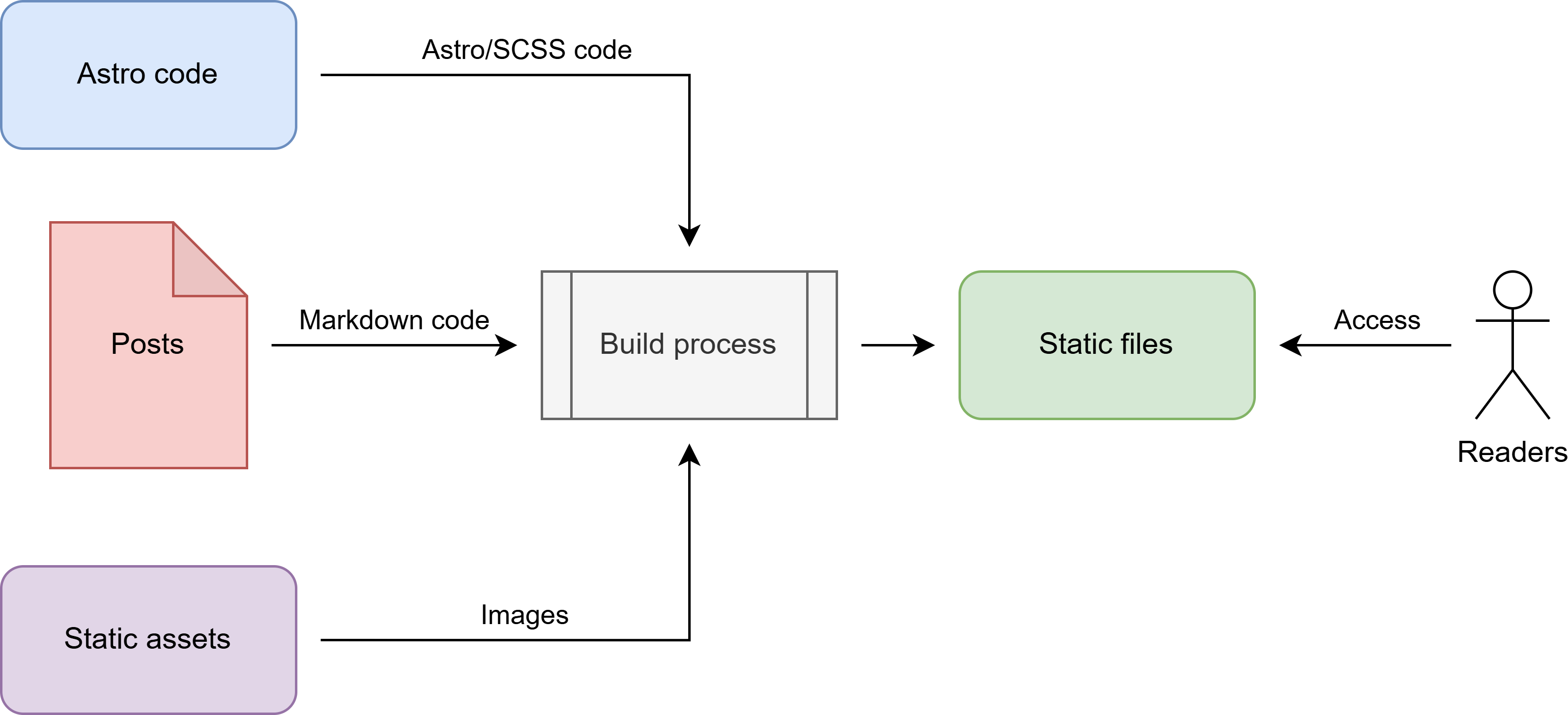
To illustrate how all of this comes together, I will leverage a diagram. For those who know me, you know that I just love useful, informative and pretty diagrams!
Styling
When it comes to styling, I do not enjoy doing it very much.

As there is a requirement that this project should be fun, we need a fun solution to implement styling. Fortunately, I found an approach that fits well - classless CSS frameworks.
Classless CSS frameworks don’t define CSS classes. Instead, they automatically style your raw HTML structure based on HTML tag semantics. For example, almost all classless frameworks apply a button style for all <button> tags. As a result, you just need to write semantic HTML code and styling will be applied automatically once you import the CSS framework.
There is a great list of available classless CSS frameworks where you can preview demo sites to choose the one that fits your taste the best. I personally chose Water.css, since I liked it best. I slightly adjusted the primary color to be more purple, added styles for icons, centered images and that was it.
Usage of classless CSS framework made styling a breeze and the outcome looks really pretty.
Infrastructure
Now that I had the content and application that can render it, I was ready to deploy my blog to the cloud. AWS is my favorite cloud. I have the most experience with it and I really like how most services work and integrate with each other.
I created a new account and was eligible for a free tier where you can have 12 months (or a quoted amount of resources for some services) for free. Additionally, I bought a domain name via Hostinger.
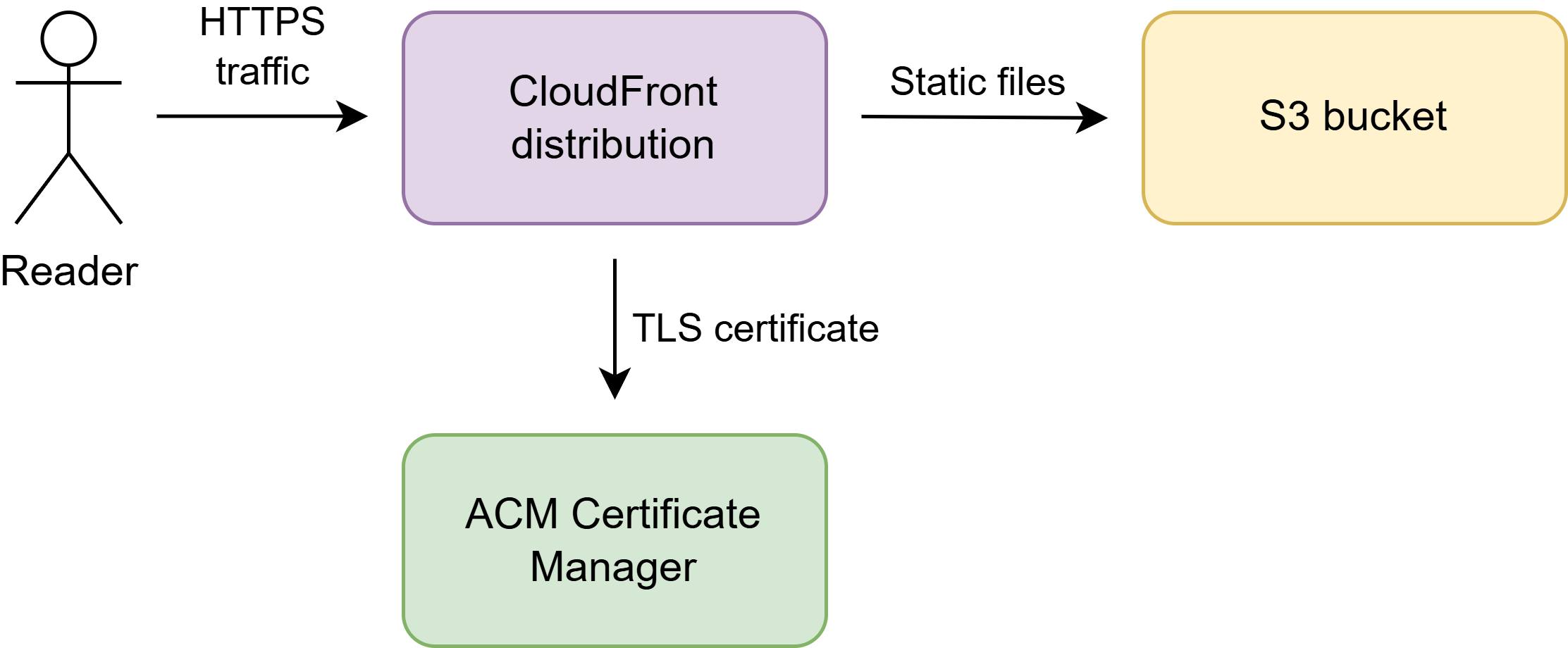
As my website is static, I do not need fancy infrastructure and servers. The main services that I use are:
- AWS S3 for storing static files.
- CloudFront content delivery network (CDN) for serving assets at edge locations for optimal performance.
- AWS Certificate Manager (ACM) for TLS certificates.
I guess you wonder, how much does all of this infrastructure cost? Domain price depends on the type of domain that you want. Price of the “.lt” domain differs from “.eu” domain. Also, you usually get a discount for the first year. You can check prices and offers here. The domain registration process was really smooth. To set things straight, I am not sponsored by Hostinger. I’m just a happy customer sharing my experience 😀.
For infrastructure, as I am currently on a free tier - it’s free.
I created an alarm to monitor the total cost and if it goes beyond a preset threshold - I will get an email. For configuring this, I followed the official guide. How and why you need to estimate and calculate infrastructure costs is an idea for upcoming blog posts, so stay tuned!
For automation, I used Jenkins that runs on my machine. It builds application artifacts - static files - and pushes them to S3 bucket. The pipeline looks very simple:
pipeline {
agent any
stages {
stage('Checkout') {
steps {
git branch: 'main', url: '<redacted Git repository>'
}
}
stage('Prepare environment') {
steps {
sh "npm i"
}
}
stage('Build') {
steps {
sh "npm run build"
}
}
stage('Upload artifacts') {
steps {
sh "aws s3 cp dist s3://<redacted S3 bucket name>/ --recursive"
}
}
stage('Invalidate distribution') {
steps {
sh "aws cloudfront create-invalidation --distribution-id <redacted distribution ID> --paths \"/*\""
}
}
}
}The infrastructure itself is created manually (I know, I know). I did not raise a requirement to automate it because:
- There was no plan to have multiple environments.
- The target infrastructure is really simple and has few connected resources.
Maybe in the future I will automate this, but right now there is no need. This also helped me once again to understand that technical solutions do not necessarily need to have all the checkboxes ticked for best practices. Engineering practices help to implement requirements and solve product needs. If there is no problem - do not solve it.
Analytics
Now that we have the application up and running, it would be great to know if someone actually visits it. There are great tools for implementing analytics, like Google Analytics, but with GDPR and cookies usage in mind, it is not that trivial anymore.

I did not want to bloat my blog with cookie consents, JavaScript code for analytics tracker and other complexities. I needed just the very basic insights. Essentially, I need this analytics solution to answer a single question - how many unique users visited a certain site (route) in a given timeframe.
To implement such a simple analytics requirement, I used CloudFront access logs + S3 storage + Athena.
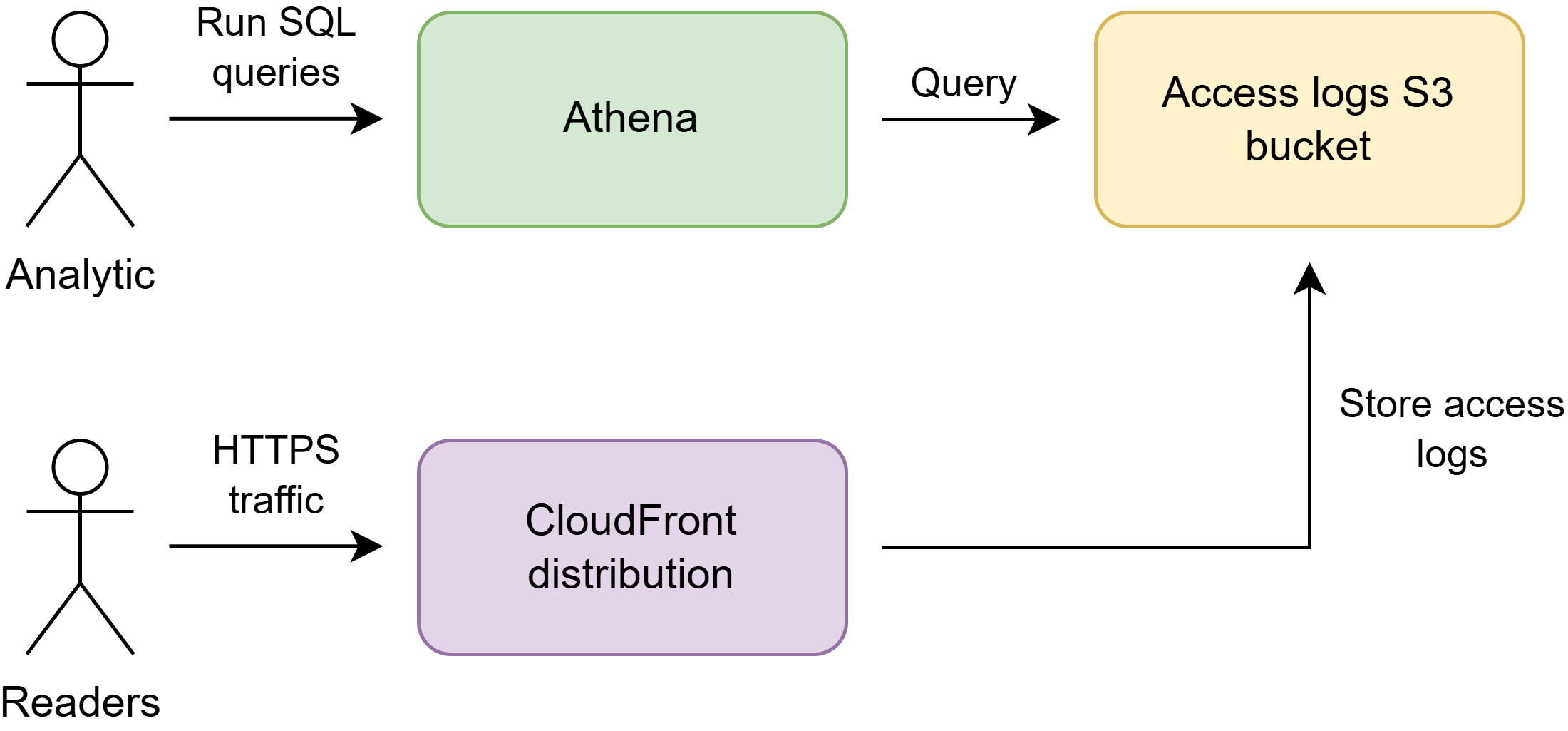
CloudFront sends access logs about each page (file) visit to S3 storage. Access logs in S3 storage are stored in a binary Parquet file format that is compressed and optimized for columnar storage. As this format is compressed, it means that file sizes are smaller, which is good for our wallet as we need to spend less money on S3 costs.
For querying data stored in S3, we leverage AWS Athena service. Athena is an interactive query service that helps you to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run and data that is scanned. You point to your data in Amazon S3, define the schema, and start querying using standard SQL.
To create a table that uses data stored in S3, I crafted a SQL query that looks like this:
CREATE EXTERNAL TABLE IF NOT EXISTS
blog_access_logs (
date STRING,
time STRING,
c_ip STRING,
cs_method STRING,
cs_uri_stem STRING,
sc_status STRING,
cs_Referer STRING,
cs_User_Agent STRING,
x_edge_result_type STRING,
time_taken STRING
)
PARTITIONED BY(
year string,
month string,
day string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
LOCATION 's3://<redacted bucket name>/logs/';This table is partitioned by date - year, month, day. Partitioning is useful, because access logs are grouped by date. Athena cost is based on the amount of data that is scanned. As our analytical queries most often need only a period of time (e.g. one month), we could scan data only for that relevant period. If there were no partitions, we would need to scan the whole S3 bucket to find relevant data and consequently pay larger costs. So this is a cost-optimization nuance that is useful for you, and your wallet.
Once the table is created and partitions are prepared, we can craft SQL queries to get the needed information. For example, with this query we can check how many unique users (unique IPs) visited each page sorted by visitor count.
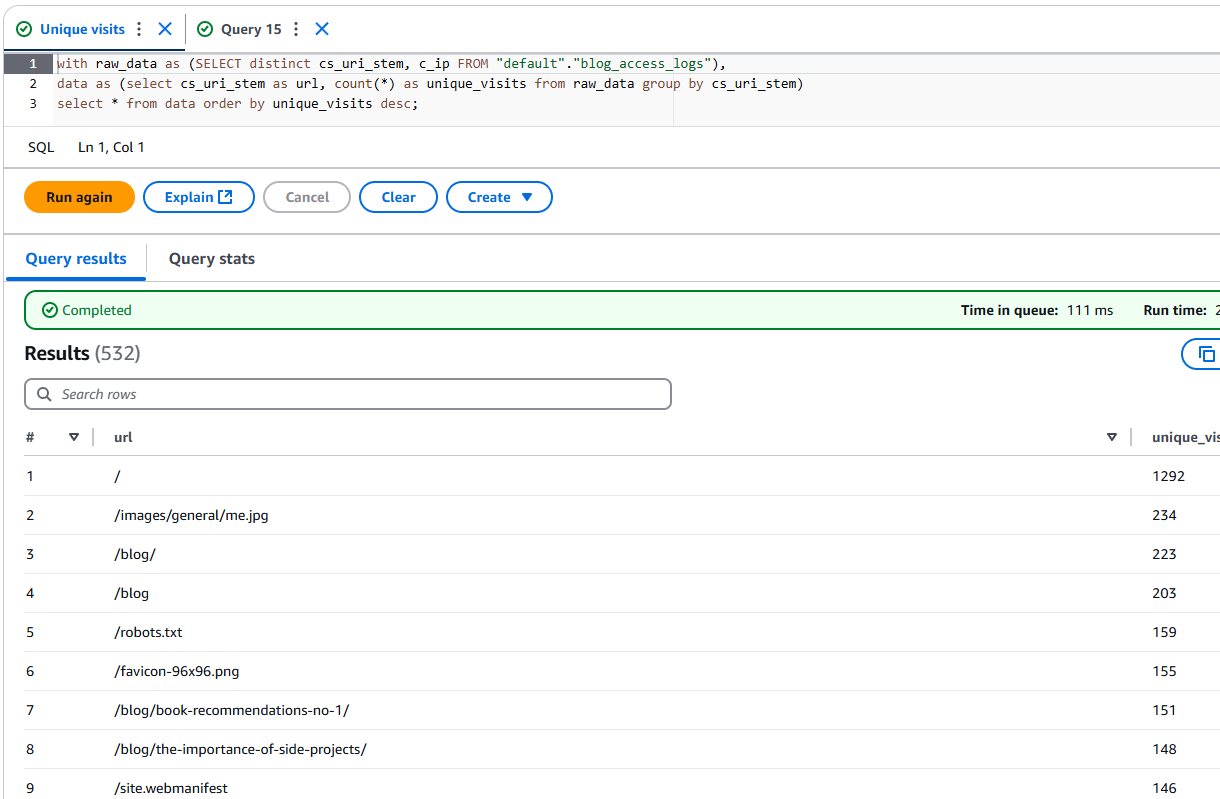
The numbers are pretty awesome. If you find this content interesting, share it with your network so we can make them skyrocket!
Conclusion
We conclude an overview of how this blog was designed and implemented. In order to evaluate, if this was a successful implementation, it is necessary to verify, if my requirements were met.

| Requirement | How the requirements were satisfied |
|---|---|
| Solution must be based on an open-source web framework. | Astro is an open-source MIT licensed web framework (https://github.com/withastro/astro). |
| Solution should be based on a free template that would offer opinionated defaults, but could also be fully customizable. | Astro blog template is open sourced, can be forked and adjusted to my needs. |
| Solution must be stored in the source control system. | All the code is stored in Github. |
| Solution must be deployed to a public cloud. | Solution was deployed to AWS cloud. |
| Solution must have the ability to accept custom CSS styling. | Astro supports SCSS styling. |
| Solution must have ability to provide basic analytics: Total page views for each entry since release of the blog, total unique users since release of the blog. | Athena queries can answer these analytical questions. |
| Infrastructure needed to run the solution must cost less than 5 EUR per month. | Current infrastructure is under free tier. |
| Solution should be interesting and fun to implement. | I had tons of fun working on this. |
| Each post should receive 50 unique reads in 2 weeks after the post is published. | There are about 70 unique reads for each post. |
| Solution must pass Lighthouse report with no less than 90 scoring for SEO, performance, accessibility and best practices areas. | Lighthouse results:  |
As we can see, all of my requirements were successfully satisfied. Also, I explored new ideas, topics, learned new things and had a lot of fun. Great success! Hopefully, you have learned something new from this post as well.