Your Knowledge, Your AI: The Benefits of Running AI Locally
Introduction
To keep up with the industry pace, I need to write something about cutting edge technologies. Is it big data? Nope, too old. Maybe blockchain? Go home, grandpa. So what is it? Of course, it’s AI!

There is a vast amount of learning material for AI already available, so what new ideas can I share with you? Well, since I am a hands-on practitioner, I will show you how I approach and solve a particular problem using AI.
Problem
I love board games. I enjoy playing them with my friends or alone (yep, solo board gaming is a thing). However, sometimes I struggle to quickly grasp certain rules and nuances of a game.
When I started playing “Gloomhaven” with my friends, for some reason I failed to understand how the “jump” mechanism worked. As a result, a new inside joke was born - “hey, Kostas, tell us how does the “jump” work”?

Generally, when you play a game, you might face situations where you are not fully sure if a certain move is valid or you just want to clarify a certain aspect of the game. In order to do so, you need to go back to the rule book, skim through many sections until you finally land on the necessary information. All of this takes time and depending on the complexity of the game can be quite a hassle. Wouldn’t it be great to have a virtual assistant that would quickly answer all of your board game questions? Well, let’s build such an assistant!
Large language models
I will not deep dive into how AI works because there are already lots of great resources out there. If you want a deep dive, check out this video.
Fundamentally, large language models are AI tools that are intelligent enough to communicate with us using natural (aka human) language. These models understand what we write/ask and generate a response in words rather than numbers or code. One of the best known implementations of a large language model is ChatGPT that most of us have dabbled in and some can’t live without.
There are multiple implementations of large language models:
- GPT (powers ChatGPT, created by OpenAI);
- Llama (open-source, created by Meta);
- DeepSeek (open-source, created by a company in China);
Each model has a different number of parameters. This number essentially defines how “smart” the model is and how successful is at answering our questions.
These days, the number of parameters varies from billions to trillions. The bigger the number of parameters, the more powerful hardware is needed to create and run the model. That is why you need to pay for your ChatGTP subscription.
But what if I don’t want to pay any fees but still want to use large language models? This is where open-source models come in.
You can run open-source models such as Llama, DeepSeek, Mistral, Phi on your computer for free. In order to do so, you can use some of these tools:
However, you need to be aware that your computer needs to be powerful enough to run them. The larger the model (both in file size and number of parameters), the more powerful your computer has to be.
I successfully ran multiple models on my workstation that has the following specifications:
- Intel Core i5-14600K
- 64GB DDR5 RAM
- NVIDIA GeForce RTX 4060 8GB GDDR6
To illustrate how we can run local large language models, let’s use Ollama. To begin with, we need to download the model. List of available models can be found here. Then we run the model and enter prompt mode where we can submit questions.
C:\Users\Kostas>ollama list
NAME ID SIZE MODIFIED
mistral:latest f974a74358d6 4.1 GB 2 weeks ago
llama3.2:latest a80c4f17acd5 2.0 GB 3 months ago
gemma3:latest a2af6cc3eb7f 3.3 GB 1 week ago
C:\Users\Kostas>ollama run llama3.2:latest
>>> Give me a short one sentence explanation of large language models.
Large language models (LLMs) are artificial intelligence systems that use complex neural networks to process and
understand human language, generating human-like responses or completing tasks such as text completion, question
answering, and translation.Additionally, we can communicate with our model via REST API. This allows us to integrate LLMs with other systems in a decoupled manner.
curl http://localhost:11434/api/generate -d '{ "model": "llama3.2", "prompt": "Give me a short one sentence explanation of large language models", "stream": false}'
{"model":"llama3.2","created_at":"2025-04-01T11:15:55.6907611Z","response":"Large language models are artificial intelligence systems that use complex neural networks to process and generate human-like language, enabling tasks such as text generation, translation, and conversation.","done":true,"done_reason":"stop","context":[128006,9125,128007,271,38766,1303,33025,2696,25,6790,220,2366,18,271,128009,128006,882,128007,271,36227,757,264,2875,832,11914,16540,315,3544,4221,4211,128009,128006,78191,128007,271,35353,4221,4211,527,21075,11478,6067,430,1005,6485,30828,14488,311,1920,323,7068,3823,12970,4221,11,28462,9256,1778,439,1495,9659,11,14807,11,323,10652,13],"total_duration":2136674800,"load_duration":65591000,"prompt_eval_count":36,"prompt_eval_duration":291000000,"eval_count":33,"eval_duration":1777000000}Finally, we can use a prettier user interface. For example, LM Studio can be used.
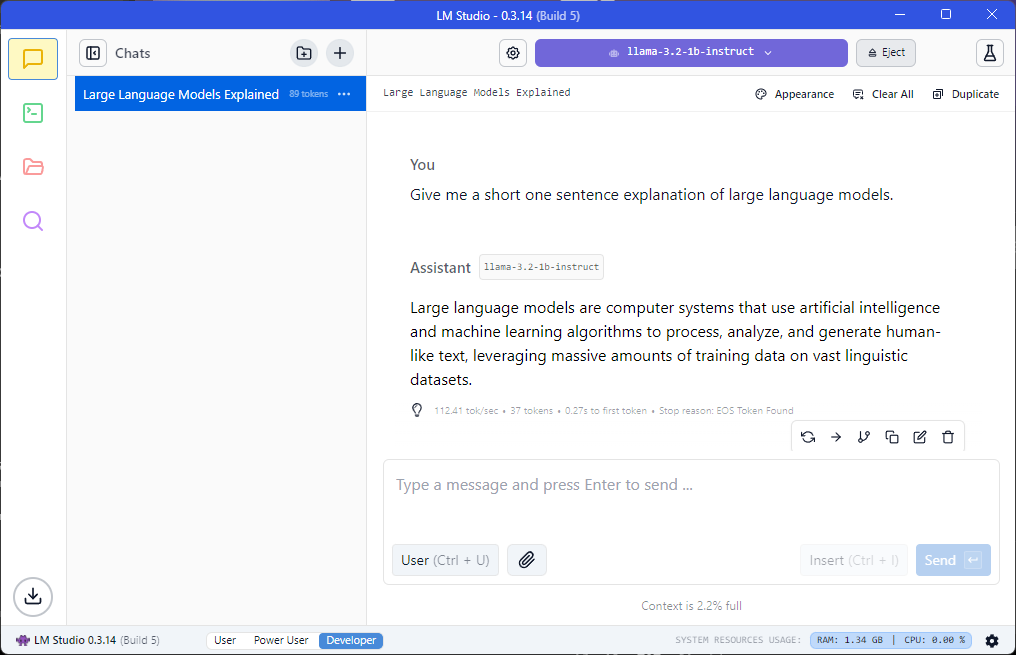
Now that we have a working environment with a gemma3 model in place (4B parameters, 3.3GB on disk), let’s use it to answer the fundamental question - how does “jump” work?
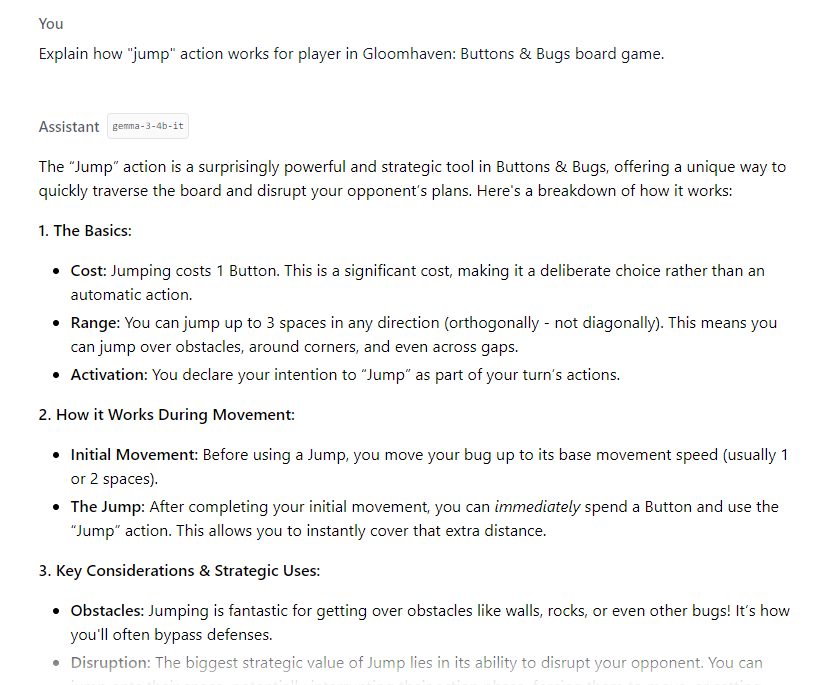
The answer we got is incorrect. It talks about “costing a button” which makes no sense.

This showcases that LLMs are not always correct and we still need to check their outputs. Our model doesn’t really know how to answer the question but tries to “guess” based on the data that it was trained on.
Usually, smaller models have less knowledge. But it is also possible that our model was trained before the release of “Gloomhaven: Buttons & Bugs”, so naturally our model is unaware about it. So how can we extend the base (aka foundational) large language model to include some additional knowledge like specific board game rules?
This is where the RAG pattern comes in.
RAG
Retrieval - Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response.
Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. RAG extends the already powerful capabilities of LLMs to specific domains or an organization’s internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improve LLM output so it remains relevant, accurate, and useful in various contexts.
Technically, RAG process looks like this:
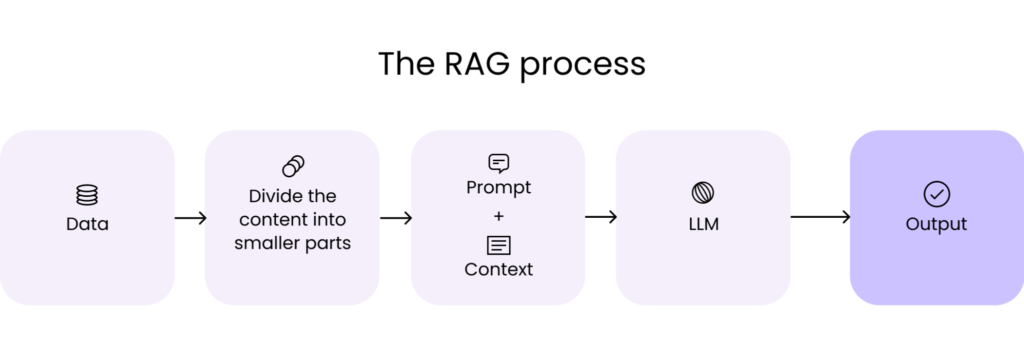
- We chunk our data (text) into segments.
- For each segment, we create an embedding. Embedding is a numeric vector representation of a segment that encodes semantic meaning and will be used in later steps.
- We store embeddings in the vector database. This can be
pgvector,marqoor others. - When we ask our RAG application a question, we create embedding for that question.
- Based on the question embedding, we search for relevant and related embeddings in our vector database.
- As a result, we get semantically relevant segments from our database.
- We extend the prompt to include relevant segments that will act as additional context.
- As a result, a large language model gets a prompt with additional context that it can use to produce more relevant results.
In our use case, we can pass PDF of game rules to a large language model. As a result, it will be able to use this information to answer our questions about the game.
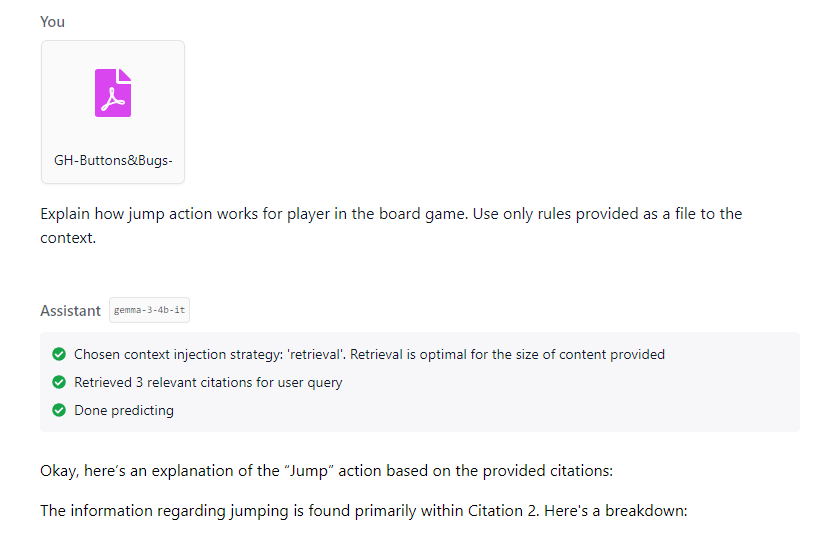

Now we get a short, concise and correct answer to our question - great success!
LangChain
LM Studio is a great tool as we get the whole RAG solution out of the box. If we want to develop custom applications that leverage large language models and RAG, LangChain is a great framework that provides us with the required building blocks. It has Python, JavaScript, C# and Java flavours.
Below you can see an example on how we can easily develop an application that reads PDF files, extracts data, creates embeddings, searches for relevant ones based on our question and passes them to the LLM model via REST API.
public class RagExample {
public void run() {
// Model for extracting embeddings
EmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("http://localhost:11434/")
.modelName("mistral:latest")
.timeout(Duration.ofHours(1))
.build();
// Embeddings will be stored in a local PostgreSQL database
EmbeddingStore<TextSegment> embeddingStore = PgVectorEmbeddingStore.builder()
.host("localhost")
.port(5632)
.database("postgres")
.user("postgres")
.password("localPassword")
.table("items")
.dimension(embeddingModel.dimension())
.dropTableFirst(true)
.createTable(true)
.build();
// Loading all PDF files from 'pdf-documents' folder
List<Document> documents = FileSystemDocumentLoader.loadDocuments(PathUtils.toPath("pdf-documents"), new ApachePdfBoxDocumentParser());
// Splitting each PDF into chunks
DocumentByParagraphSplitter splitter = new DocumentByParagraphSplitter(1024, 256);
// Embedding PDF documents
for (Document document: documents) {
List<TextSegment> textSegments = splitter.split(document);
for (TextSegment textSegment: textSegments) {
Embedding embedding = embeddingModel.embed(textSegment).content();
embeddingStore.add(embedding, textSegment);
}
}
// Model for answering questions
ChatLanguageModel chatLanguageModel = OllamaChatModel.builder()
.baseUrl("http://localhost:11434/")
.modelName("llama3.2:latest")
.temperature(0.0)
.timeout(Duration.ofHours(1))
.build();
String question = "Explain how jump action works for player in the board game. Use only rules provided as a file to the context.";
// Retrieving relevant embeddings (PDF file paragraphs)
Embedding queryEmbedding = embeddingModel.embed(question).content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(5)
.build();
List<EmbeddingMatch<TextSegment>> relevantEmbeddings = embeddingStore.search(embeddingSearchRequest).matches();
// Building context to be passed in our prompt
StringBuilder context = new StringBuilder();
for (EmbeddingMatch<TextSegment> match : relevantEmbeddings) {
context.append(match.embedded().text()).append("\n");
}
String message = "Answer the following question: " + question + "\n" +
"Use the following context to answer the question: " + context;
// Inferring (retrieving) answer to our question
String answer = chatLanguageModel.generate(message);
System.out.println(answer);
}
}With this approach we can start building our own AI-driven applications using local LLM models with RAG pattern.
Results
In this post we learned more about large language models, gained insights on how to run models locally using ollama and LM Studio tools, understood RAG pattern and took a glimpse into LangChain framework. Ultimately, we built a board game assistant and finally understood how “jump” works - hooray!
But what does “pierce” mean? Well, let me ask my new friend…
